Module 6 - Tuần 3: Multilayer Perceptron & Metrics for Classification
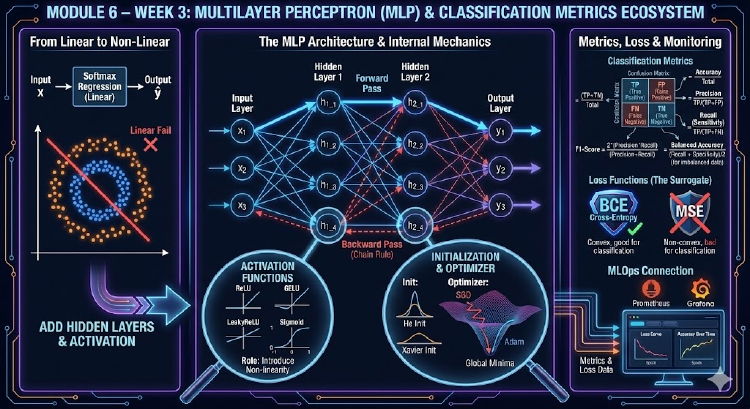
Tuần 3 của Module 6 nâng cấp từ Softmax Regression lên Multilayer Perceptron (MLP), đi kèm khảo sát Activation, Initialization, Optimizer và các hệ metric dành cho bài toán phân loại. Sinh viên vừa học công thức forward/backward, vừa code PyTorch, đồng thời kết nối với thế giới MLOps qua Prometheus & Grafana.
- 4 min read
🎓 All-in-One Course 2025 – aivietnam.edu.vn
📘 Study Guide: Module 6 – Week 3
🧩 Chủ đề: Multilayer Perceptron & Metrics for Classification
💡 Tuần này là bước chuyển từ “mô hình tuyến tính” sang “mạng nơ-ron sâu”: MLP, Activation, Initialization, Optimizer – và cách đo lường mô hình phân loại bằng các hệ metric khác nhau để chuẩn bị cho bài Loss ở các tuần sau.
📅 Lịch trình học và nội dung chính
🧑🏫 Thứ 3 – Ngày 18/11/2025
(Buổi warm-up – MSc. Quốc Thái)
Chủ đề: MLP cơ bản – từ Perceptron tới Multi-layer Perceptron
Nội dung:
Nhắc lại Softmax/Logistic Regression, lý do phải thêm hidden layer.
Thảo luận các bước trong MLP pipeline: chuẩn bị dữ liệu → chuẩn hóa → xây network → khởi tạo tham số.
Làm ví dụ tính tay forward qua 1 hidden layer:
$$ \mathbf{h} = \sigma(W_1 \mathbf{x} + \mathbf{b}_1), \quad \hat{\mathbf{y}} = \text{softmax}(W_2 \mathbf{h} + \mathbf{b}_2) $$
👨🏫 Thứ 4 – Ngày 19/11/2025
(Buổi học chính – Dr. Quang Vinh)
Chủ đề: Xây dựng MLP – Forward & Backward
Nội dung:
So sánh Softmax Regression vs MLP.
Giải thích forward/backward nhiều layer bằng chain rule.
Các câu hỏi khi design network:
- Bao nhiêu hidden layers, mỗi layer bao nhiêu neurons?
- Đặt activation ở đâu và vì sao “affine → non-linear → affine” mới tăng được năng lực biểu diễn.
- Khi nào dùng
nn.ReLU()trong__init__vsF.relu()trongforward.
Cài đặt MLP bằng PyTorch và xem kích thước từng layer.
⚙️ Thứ 5 – Ngày 20/11/2025
(Buổi MLOps – TA Nguyễn Thuận)
Chủ đề: Prometheus & Grafana – Monitoring hệ thống AI
Nội dung:
- Kết nối MLFlow tuần trước sang monitoring.
- Pipeline: MLP → log metrics → Prometheus → Grafana dashboard.
- Demo tracking loss, accuracy, batch time, GPU memory.
🧠 Thứ 6 – Ngày 21/11/2025
(Buổi học chính – Dr. Quang Vinh)
Chủ đề: Activation, Initialization & Optimizer
Nội dung:
- Các activation quan trọng:
- ReLU, LeakyReLU, GELU, Sigmoid, Tanh.
- Vì sao activation nằm giữa các fully-connected layers.
- Initialization:
- He init cho ReLU
- Xavier cho Tanh/Sigmoid
- Optimizer:
- SGD + Momentum vs Adam
📊 Thứ 7 – Ngày 22/11/2025
(Buổi chuyên đề – Dr. Đình Vinh)
Chủ đề: Metrics cho phân loại
Nội dung:
- Confusion Matrix: TP, TN, FP, FN.
- Binary:
- Accuracy, Precision, Recall, Specificity, FPR, FNR, F1.
- Multiclass:
- Micro/Macro/Weighted F1, Balanced Accuracy, \(F_\beta\).
- Multilabel:
- Exact Match, 0/1 Loss, Hamming Loss.
- Vì sao metric không differentiable → dùng Loss làm surrogate.
👨🎓 Chủ nhật – Ngày 23/11/2025
(Buổi ôn tập – TA Đình Thắng)
Chủ đề: MLP – Exercise & Mini Project
Nội dung:
- Tóm tắt forward/backward, activation, init, optimizer.
- Bài tập giấy + code (ReLU → GELU).
- Chạy MLP, log Accuracy/F1/Recall/Balanced Accuracy.
📌 Điểm nhấn và kiến thức chính
✅ Từ Softmax Regression tới MLP
Softmax Regression là mô hình tuyến tính:
$\hat{\mathbf{y}} = \text{softmax}(W\mathbf{x} + \mathbf{b})$MLP thêm hidden layers + activation:
$\mathbf{h}^{(l)} = \sigma(W^{(l)} \mathbf{h}^{(l-1)} + \mathbf{b}^{(l)})$
✅ Activation – Initialization – Optimizer
- ReLU: nhanh nhưng có dying ReLU.
- LeakyReLU/GELU: giữ gradient tốt hơn.
- Initialization:
- He init ↔ ReLU
- Xavier ↔ Sigmoid/Tanh
- Optimizer:
- SGD (ổn nhưng cần tuning)
- Adam (adaptive learning rate)
✅ Backprop qua nhiều layer
Backprop chỉ là chain rule lặp lại:
$$ \frac{\partial \mathcal{L}}{\partial W^{(L)}} = \frac{\partial \mathcal{L}}{\partial \hat{\mathbf{y}}} \frac{\partial \hat{\mathbf{y}}}{\partial W^{(L)}} $$Gradient lan từ output về input → dễ gây vanishing/exploding.
✅ Metrics & Loss
- Binary: Accuracy, Precision, Recall, Specificity, F1.
- Multiclass: Micro/Macro/Weighted F1, Balanced Accuracy.
- Multilabel: Exact Match, Hamming Loss.
Metric = đo chất lượng.
Loss = để tối ưu bằng gradient descent.
Metric không differentiable → dùng Loss surrogate như Cross-Entropy.
📚 Tài liệu đi kèm
M06W03 – Study Guide
📄 M06W03 – Study GuideM06W03 – Multilayer Perceptron Slides
📄 M06W03 – Multilayer Perceptron SlidesM6W2D4+6_Prometheus_Grafana_MLOPs
📄 M6W2D4+6_Prometheus_Grafana_MLOPsM06W03 – Insight into MLP
📄 M06W03 – Insight into MLPM06W03 – Metrics for Classification
📄 M06W03 – Metrics for Classification
🧠 Repository managed by AI Vietnam Team Hub
📍 Blog thuộc series All-in-One Course 2025 – chương trình đào tạo toàn diện AI, Data Science, và MLOps tại aivietnam.edu.vn
🧠 Repository managed by AI Vietnam Team Hub
📍 Blog thuộc series All-in-One Course 2025