Module 6 - Tuần 1 - Xây dựng Loss Function cho Linear Regression & Logistic Regression từ đầu
Linear Regression vs Logistic Regression
- 4 min read
📘 Xây dựng Loss Function cho Linear & Logistic Regression từ đầu
AIO Vietnam – Module 6, Week 1 – Ngày 18/11/2025
🎓 Bài viết dựa trên nội dung bài giảng:
M6W1D4+6 – Learn to Build Loss Function for Linear Regression & Logistic Regression from the Ground Up
(Tài liệu học nội bộ AIO2025)
🌟 Giới thiệu
Loss function là trái tim của mọi mô hình Machine Learning.
Bài blog này giúp bạn hiểu sâu cách tự xây dựng Loss Function từ con số 0, theo đúng tinh thần “ground-up”:
- Từ trực giác → mô hình tuyến tính
- Từ phân phối Bernoulli → Log-Likelihood
- Từ Log-Likelihood → Binary Cross-Entropy (BCE)
- Từ đạo hàm → Hessian → chứng minh convexity
Kết quả: bạn hiểu bản chất Logistic Regression, chứ không chỉ “nhớ công thức”.
🔎 Nội dung chính
1️⃣ Từ Linear Regression → Logistic Regression
Linear Regression phù hợp cho dự báo liên tục nhưng thất bại trong phân loại vì:
- Output có thể ngoài khoảng [0, 1], không thể xem là xác suất
- Khi kết hợp với sigmoid + MSE → gradient nhỏ, mô hình học rất chậm
- Loss trở thành non-convex, dễ bị kẹt
Kết luận: cần một Loss Function mới phù hợp bản chất xác suất.
2️⃣ Loss Function cho Linear Regression
- Hàm giả thuyết:
y_hat = θ^T x - Loss chuẩn cho hồi quy:
MSE = 1/(2m) * Σ (y_hat - y)^2 - MSE là convex, dễ tối ưu và hội tụ nhanh
- Nhưng không phù hợp cho Logistic Regression
3️⃣ Xây dựng Binary Cross-Entropy từ phân phối Bernoulli
Với phân loại nhị phân:
- Nhãn tuân theo Bernoulli
- Likelihood:
L = y*log(y_hat) + (1-y)*log(1-y_hat) - Đổi dấu để tối thiểu hoá:
BCE = -[ y log(y_hat) + (1-y) log(1-y_hat) ]
BCE là Loss được suy ra từ nguyên lý thống kê, không phải ngẫu hứng.
4️⃣ Logistic Regression dạng vector hoá
- Dữ liệu dưới dạng ma trận:
X (m×n), θ (n×1) - Mô hình:
y_hat = σ(Xθ) - Gradient gọn:
∇θ L = X^T (y_hat - y)
Khi vector hoá, mô hình nhanh – gọn – tối ưu hiệu quả.
5️⃣ BCE là convex – Phân tích Hessian
- Đạo hàm bậc hai của BCE:
∂²L/∂θ² = x² * y_hat * (1 - y_hat) - Vì các phần tử đều ≥ 0 → Hessian không âm
Do đó:
- BCE convex
- Logistic Regression có global minimum duy nhất
- Gradient Descent luôn hội tụ
💡 Vì sao bài viết này hữu ích?
✔ Hiểu “tận gốc” thay vì học thuộc công thức
✔ Biết vì sao MSE không phù hợp cho classification
✔ Nắm nguyên lý thống kê của Logistic Regression
✔ Thấy được vai trò của convexity trong tối ưu hóa
✔ Dễ dàng tự code lại Logistic Regression bằng NumPy
🖼️ Gợi ý minh hoạ cho blog
Bạn có thể thêm 1 trong 3 hình minh hoạ sau:
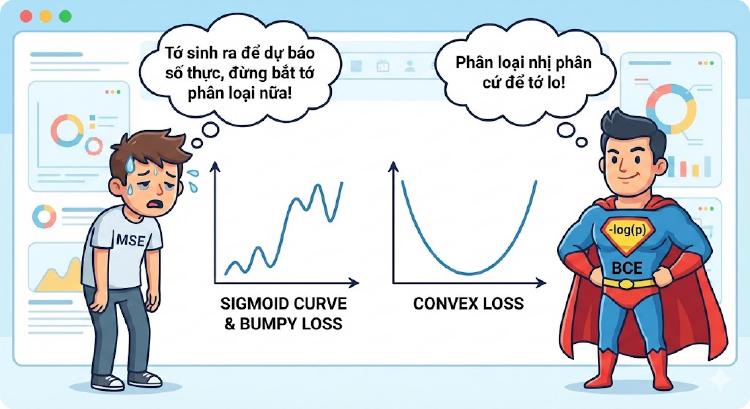
🎨 Concept 1 – MSE vs BCE (Cartoon)
- MSE: mặt mệt mỏi, bị “sigmoid đè phẳng gradient”
- BCE: siêu anh hùng có đồ thị convex mượt
- Câu thoại: “Phân loại cứ để tôi!”
🎨 Concept 2 – Infographic Flow
Timeline 5 bước:
- Linear model
- Sigmoid
- Bernoulli
- Likelihood → BCE
- Convex optimization
🎨 Concept 3 – Landscape tối ưu
- Trái: MSE + sigmoid → đồ thị gồ ghề
- Phải: BCE → hình cái bát mượt
- Hai nhân vật nhỏ đang “leo núi” và “trượt xuống đáy”
📚 Tài liệu tham khảo
- AIO2025 – Module 6 Week 1
- Andrew Ng – CS229
- DeepLearning.AI – Logistic Regression
- Bishop – Pattern Recognition and Machine Learning
✨ Kết luận
Đây là một trong những bài học nền tảng nhưng cực kỳ quan trọng trong Machine Learning.
Hiểu sâu Loss Function giúp bạn:
- Tránh mô hình học sai bản chất
- Tối ưu đúng hướng
- Tự tin triển khai Logistic Regression thực chiến
Chúc bạn học thật vui và hiểu thật sâu! 🚀
📂 Tài liệu đi kèm:M6W1D4+6_Learn_to_Build_LossFunction_for_LinearRegression_and_LogisticRegression_from_the_GrounthUp