Module 6 - Tuần 4: FPT Forecasting Challenge
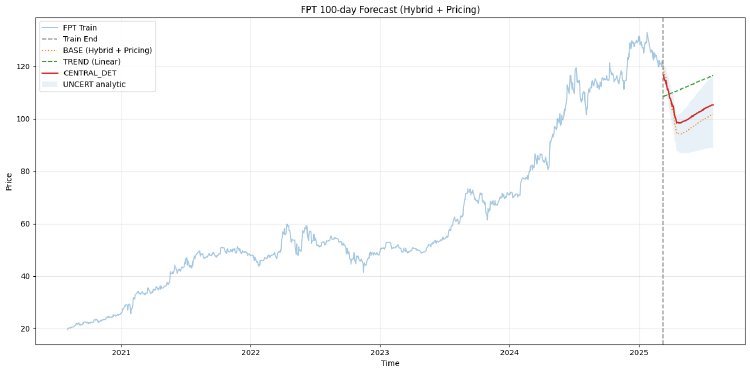
Dự báo giá cổ phiếu FPT 100 ngày bằng mô hình Hybrid Linear + ML + Regime-aware Pricing
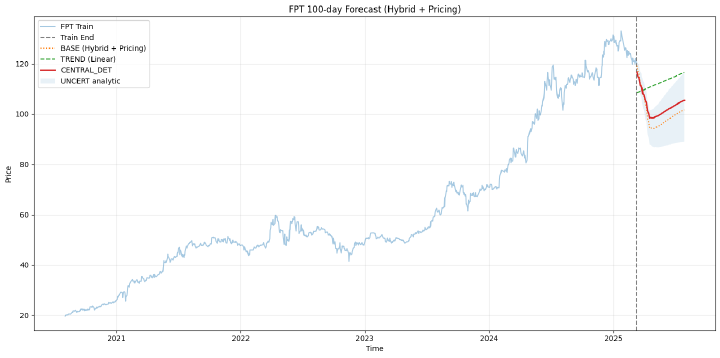
Dự báo giá cổ phiếu FPT 100 ngày bằng mô hình Hybrid Linear + ML + Regime-aware Pricing
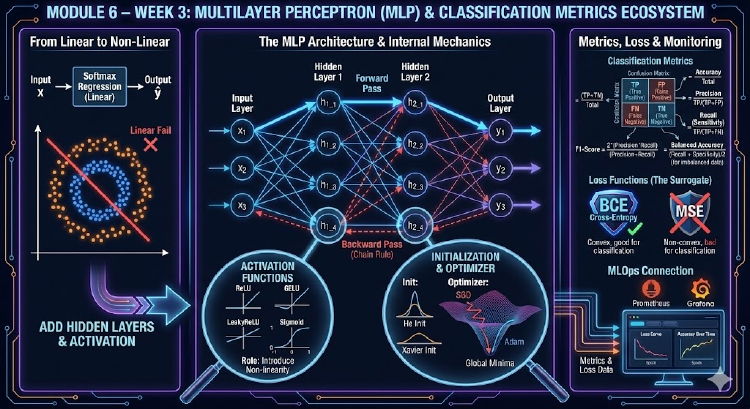
Tuần 3 của Module 6 nâng cấp từ Softmax Regression lên Multilayer Perceptron (MLP), đi kèm khảo sát Activation, Initialization, Optimizer và các hệ metric dành cho bài toán phân loại. Sinh viên vừa học công thức forward/backward, vừa code PyTorch, đồng thời kết nối với thế giới MLOps qua Prometheus & Grafana.

Logistic Regression, Apache Airflow, Metrics

Tuần 3 là tuần 'cây cối nở rộ': chúng ta ôn tập toàn bộ họ nhà Tree từ Random Forest đến XGBoost, rồi học LightGBM!
Tuần 3 là tuần 'cây cối nở rộ': chúng ta ôn tập toàn bộ họ nhà Tree từ Random Forest đến XGBoost, rồi học LightGBM và SHAP, kèm MLOps với Docker và project dự báo doanh số!

Tuần này chúng ta tiếp nối series Tree-based models với Gradient Boosting và XGBoost, học từ ví dụ tính tay đến code thật, kèm bonus 1 ngày FastAPI để đưa mô hình lên web!

Hệ thống phân loại publication abstract theo các chủ đề khoa học (astro-ph, cond-mat, cs, math, physics) với giải thích token-level, KNN bỏ phiếu trọng số cải tiến, và dashboard Streamlit trực quan.
Mô hình dự đoán bệnh tim mở rộng hướng kết hợp ensemble learning và tăng cường dataset bằng dữ liệu ảnh.
Tuần mở màn của Module 4 tập trung vào hai thuật toán ensemble chủ lực (Random Forest, AdaBoost), thực hành dựng demo bằng Gradio (Basic MLOps), và mở rộng nền tảng về dữ liệu chuỗi thời gian – một tuần học thiên về thực hành, ứng dụng và kết nối giữa mô hình & triển khai.
Tuần thứ ba của Module 3 mở màn với hành trình chinh phục Decision Tree – từ kiến thức nền tảng đến ứng dụng vào bài toán phân loại và dự đoán. Song song đó, chúng ta tiếp tục khám phá sức mạnh của Cloud trong lưu trữ dữ liệu, và nâng cấp kỹ năng phân tích với Excel – một tuần học đậm chất thực chiến và ứng dụng đa nền tảng!

Tuần đầu tiên của Module 3 tập trung vào kỹ năng xử lý dữ liệu bảng, trực quan hóa dữ liệu và các kỹ thuật phân tích từ cơ bản đến nâng cao, kết hợp công cụ Pandas, ETL Pipelines và Excel. Đây là bước đệm quan trọng để ứng dụng vào các bài toán AI thực tế.
Tuần thứ hai của Module 3 mở màn bằng khám phá K-Means clustering và KNN algorithms, cùng với PySpark data engineering – một tuần học đậm chất thực chiến và ứng dụng!

Hệ thống phân loại tin nhắn spam/ham nâng cao với khả năng giải thích, được xây dựng bằng Streamlit và các kỹ thuật học máy/học sâu hiện đại.