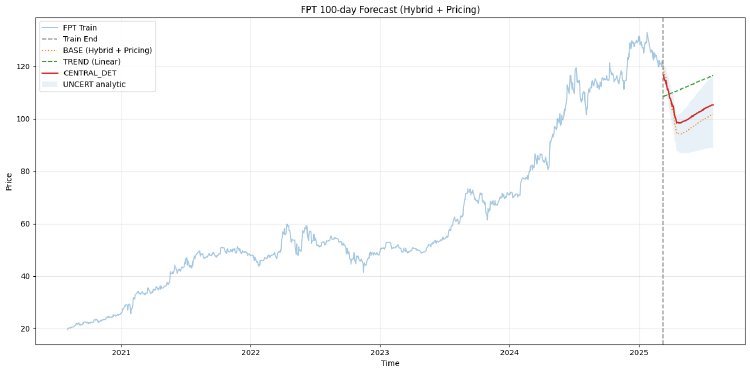
Module 6 - Tuần 4: FPT Forecasting Challenge
Dự báo giá cổ phiếu FPT 100 ngày bằng mô hình Hybrid Linear + ML + Regime-aware Pricing
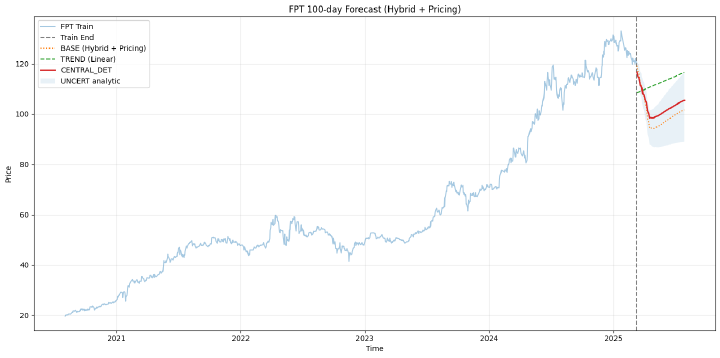
Dự báo giá cổ phiếu FPT 100 ngày bằng mô hình Hybrid Linear + ML + Regime-aware Pricing
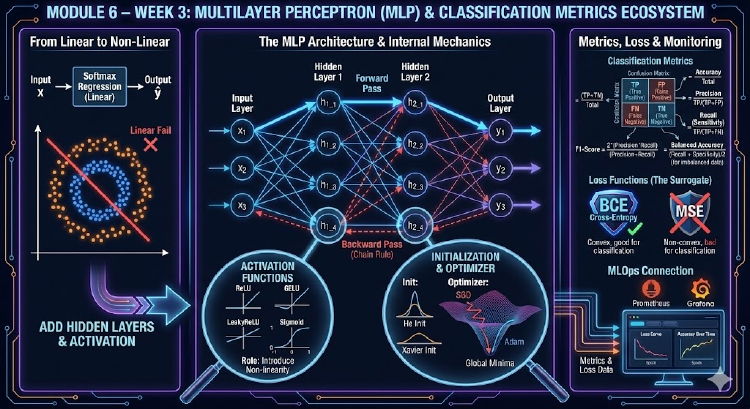
Tuần 3 của Module 6 nâng cấp từ Softmax Regression lên Multilayer Perceptron (MLP), đi kèm khảo sát Activation, Initialization, Optimizer và các hệ metric dành cho bài toán phân loại. Sinh viên vừa học công thức forward/backward, vừa code PyTorch, đồng thời kết nối với thế giới MLOps qua Prometheus & Grafana.

Logistic Regression, Apache Airflow, Metrics
Dự báo giá cổ phiếu FPT 100 ngày bằng mô hình Hybrid Linear + ML + Regime-aware Pricing
Tuần 3 của Module 6 nâng cấp từ Softmax Regression lên Multilayer Perceptron (MLP), đi kèm khảo sát Activation, Initialization, Optimizer và các hệ metric dành cho bài toán phân loại. Sinh viên vừa học công thức forward/backward, vừa code PyTorch, đồng thời kết nối với thế giới MLOps qua Prometheus & Grafana.
Logistic Regression, Apache Airflow, Metrics

Các Thước Đo Đánh Giá Mô Hình Hồi Quy
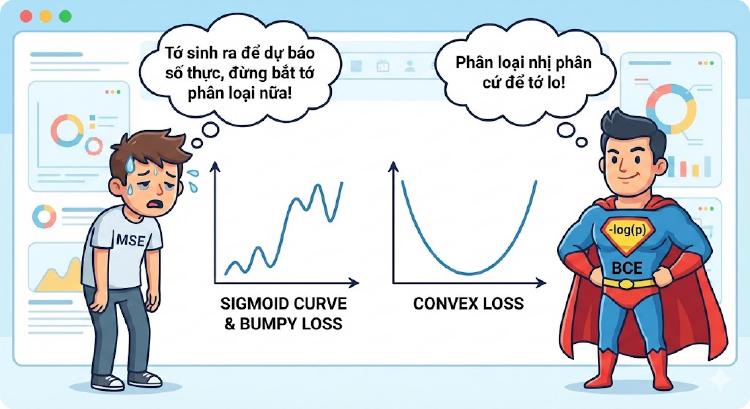
Linear Regression vs Logistic Regression
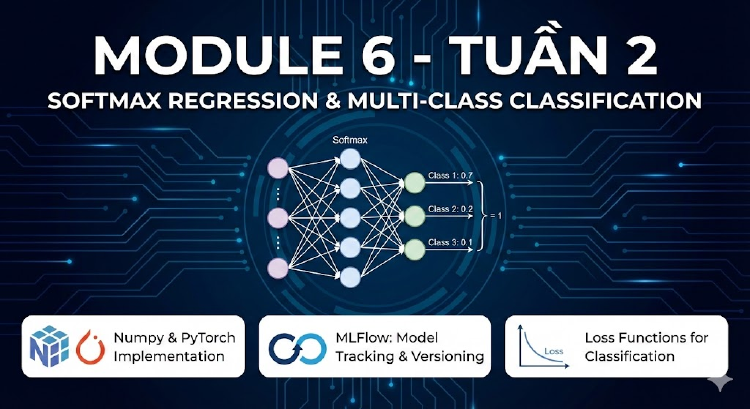
Tuần 2 của Module 6 đi sâu vào Softmax Regression cho bài toán phân loại đa lớp, cùng với ứng dụng thực tế trong MLOps bằng MLFlow. Sinh viên được thực hành tính toán, lập trình với Numpy và PyTorch, và tìm hiểu cách quản lý mô hình bằng MLFlow.
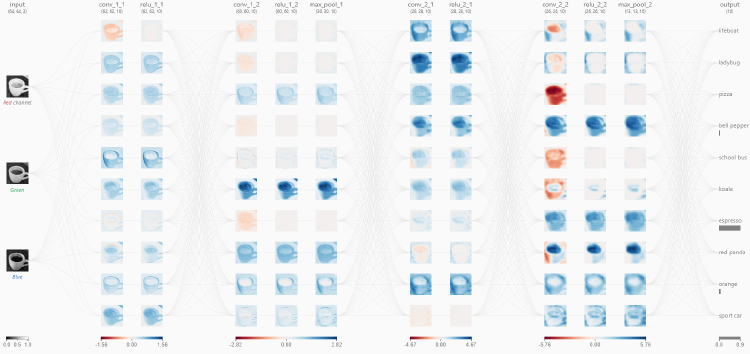
Module 7 đi sâu vào Mạng Nơ-ron Tích chập (CNN). Chúng ta sẽ đi từ những hạn chế của MLP truyền thống trong xử lý ảnh đến 'Góc nhìn Bộ lọc' của CNN, khám phá các cơ chế chính như Stride, Padding, Pooling, và các khái niệm nâng cao như Backpropagation và Tích chập 1x1.

Tuần 4 của Module 5 tập trung vào ứng dụng nâng cao của Regression, kết hợp chọn đặc trưng thông minh (Correlation & F-statistics), tối ưu mô hình qua Ensemble, và mở rộng thành Agent AI hỗ trợ thẩm định giá nhà thực tế.

Tuần 3 của Module 5 tập trung vào nền tảng của Giải thuật Di truyền (Genetic Algorithms), kết hợp MLOps AWS và giải thích mô hình qua SHAP trong XAI. Hướng dẫn cài đặt Python cơ bản, thảo luận randomness, và áp dụng GA trong bài toán tối ưu hóa & dự đoán thực tế.
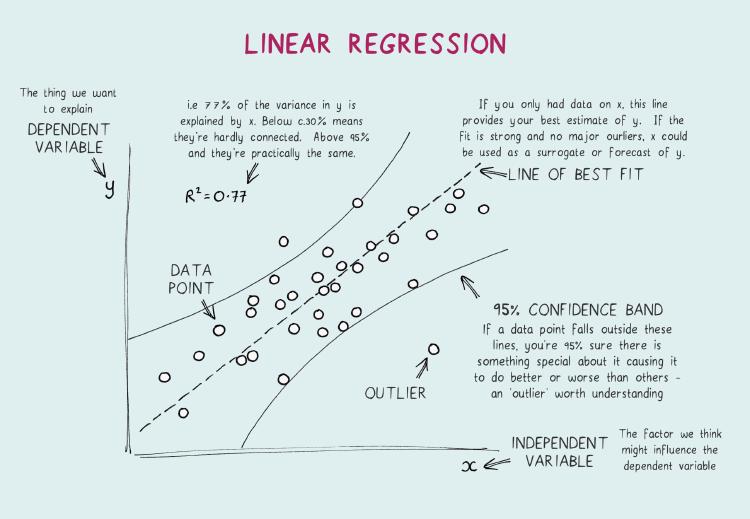
Tuần 2 của Module 5 đào sâu vào Advanced Linear Regression — từ vector hóa công thức đến triển khai dự án ML thực chiến với Feast. Blog này tập trung vào Linear Regression và MLOps, trong khi XAI (LIME–ANCHOR–SHAP) sẽ được tổng hợp trong một bài blog đặc biệt sắp tới!